If you are a Home Assistant enthusiast and are interested in long term storage of sensor and other data, you will be using InfluxDB. InfluxDB is a time-series database, different from SQLite and MariaDB. Over time your InfluxDB database can grow and grow…becoming unwieldy and possibly slow. Fortunately there are solutions to manage the volume of data stored in your InfluxDB Home Assistant database.

Managing your InfluxDB Data
This post covers a two pronged approach to managing your Home Assistant InfluxDB data. First, you can setup InfluxDB includes/excludes in Home Assistant which limit what data is sent to InfluxDB in the first place. This is highly configurable and what you want to keep long term is entirely up to you. Second, you can downsample your data.
What is downsampling? Let’s say you have sensors (like solar power generation, or whole house power monitoring) that logs data every few seconds or every minute. Over time, this high resolution data become enormous and unwieldy. And in two years do you really need minutely power sensor data? Probably not.
However, having some recent history with high resolution data can be very helpful for dashboards and queries. But maybe for medium term storage you can downsample your minutely data to 5 minute samples. And for long term retention maybe you are OK with 15 minute samples.
In this post I’ll cover a great downsampling solution for InfluxDB 1.x that was discussed in the Home Assistant Forums. I can’t take credit for the underlying code. And, I’ll cover using Home Assistant Includes/Excludes for even more data filtering. The forum discussion focused on InfluxDB running in Docker (and by extension, using the InfluxDB HA add-on). However, I run InfluxDB in a LXC container on Proxmox. So I tailored this tutorial for InfluxDB running in a LXC container, and made some other tweaks as well. This tutorial would also work for a vanilla InfluxDB installed in a VM. Combining both downsampling and includes/excludes gives you the best of both worlds.
Why InfluxDB in a LXC Container?
Home Assistant has an InfluxDB add-on that lets you install and configure InfluxDB in just a few clicks. So why am I running InfluxDB in a LXC container? There are four reasons why I like separating InfluxDB from my HAOS instance:
1. I use the Google Drive backup add-on which stores my HA configuration in the cloud. I have limited space in Google Drive and I like keeping a few weeks of HAOS backups. So keeping the nightly backups small is important. If InfluxDB is running in my HAOS server, the HA backup will include the whole InfluxDB database.
2. When restoring Home Assistant if your backup is over 1GB the restore process is more complicated. So I really want to keep backups under 1GB. Check out my tutorial on how to restore Home Assistant for more details.
3. My configuration uses a cron job perform the hourly downsampling. With HAOS (which I strongly recommend), you are very limited at the OS level what you can do. So you have to do a somewhat complicated workaround that doesn’t use cron to do your scheduled downsampling jobs.
4. Because I’m using Proxmox I can automate entire LXC container backups. I send these backups to my Synology NAS. It has tons of free space, so backing up large databases is no problem. I then replicate the Proxmox backups to Wasabi for safe keeping.
Additional InfluxDB Tutorials
If you want a guide on how to install InfluxDB in a LXC container on Proxmox, you can check out my tutorial Home Assistant: Installing InfluxDB (LXC). If you want to learn about backing up InfluxDB, read my InfluxDB 1.x Automated Backups tutorial. If you are interested in using Proxmox and want a full install guide, check out my tutorial Home Assistant: Proxmox Quick Start Guide.
Downsampling Strategy
How long you want to keep your data and at what resolutions is entirely up to you. In this post we will setup the downsampling schedule to keep full resolution data for 6 months, 5-minute sample data for an additional 18 months, and 15-minute samples forever. The figure below maps out the downsampling. You can easily modify the parameters in the scripts to change the time periods and downsampling rates.
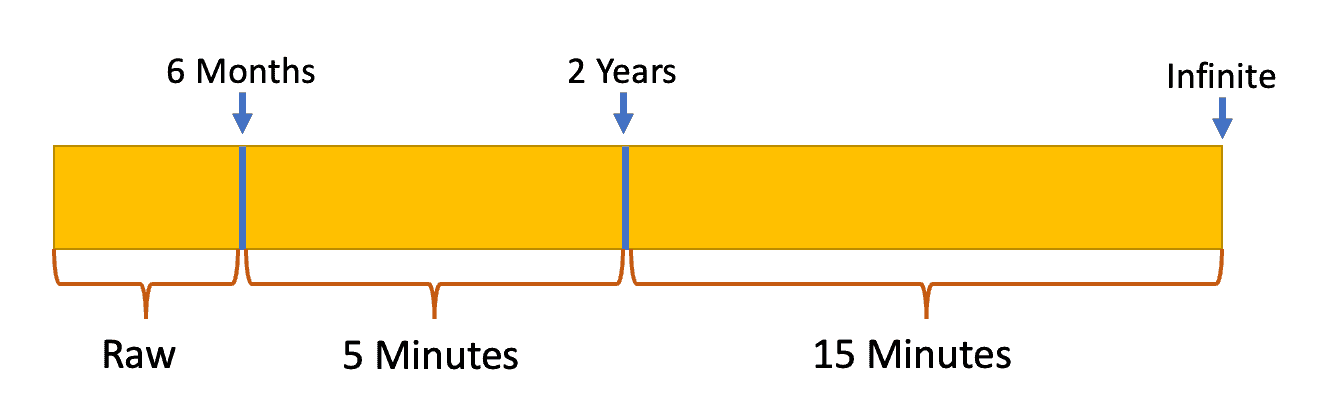
To downsample the data we create two new retention policies for data in your Home Assistant InfluxDB database. Then we run InfluxDB commands that copy and downsample the appropriate data into these two new retention policies. After the initial downsampling, we then schedule a cron job to run hourly that moves and downsamples data on an ongoing basis. This is a ‘set it and forget’ job. Just monitor the disk usage of your InfluxDB LXC container to make sure you don’t run out of space over time.
Tip: Don’t use the InfluxDB HA sensor that’s floating around on forums to accurately assertain how large your InfluxDB Home Assistant database is. That sensor can be wildly inaccurate. I suggest using the Home Assistant Proxmox integration and monitor the disk space of your LXC container.
InfluxDB Downsampling
For the purposes of this tutorial I’ve used my InfluxDB 1.x Automated Backups post for doing InfluxDB Backups. So I have a /backups directory at the root level of my LXC container, where we will put the cron job log. The paths you use for the scripts is not important, so feel free to put the scripts anywhere you want and modify paths as needed. Lastly, my Home Assistant InfluxDB database is called home_assistant and the login username is homeassistant. Modify as needed for your setup.
Warning: Make a backup of your InfluxDB database before following this procedure. Nothing should go wrong, but you never know. Do this at your own risk. Check out my InfluxDB 1.x Automated Backups post for one way to do backups. Again, this procedure assumes InfluxDB is running in a LXC container, not Docker, and not the HAOS add-on.
- SSH into your InfluxDB LXC container as root.
- Run the command with your InfluxDB username, password and HA database name.
influx -precision rfc3339 -username 'homeassistant' -password 'yourpassword' -database 'home_assistant'
3. Once at the InfluxDB command prompt run the two commands below. This creates our retention policies for 6 months to 2 years, and 2 years to infinite.
CREATE RETENTION POLICY "y2_5m" ON "home_assistant" DURATION 104w2d REPLICATION 1
CREATE RETENTION POLICY "inf_15m" ON "home_assistant" DURATION INF REPLICATION 1
4. The two select commands below copy all the data older than six months but less than 24 months to the y2_5m grouping and data older than 24 months into the inf_15m grouping with 15-minute samples. Run these commands while still in the InfluxDB CLI.
SELECT mean(value) AS value,mean(crit) AS crit,mean(warn) AS warn INTO "home_assistant"."y2_5m".:MEASUREMENT FROM "home_assistant"."autogen"./.*/ WHERE time < now() -26w and time > now() -104w GROUP BY time(5m),*
SELECT mean(value) AS value,mean(crit) AS crit,mean(warn) AS warn INTO "home_assistant"."inf_15m".:MEASUREMENT FROM "home_assistant"."autogen"./.*/ WHERE time < now() -104w GROUP BY time(15m),*
5. Now that your old data is moved, we need to run a cron job to periodically move new data into these groups. InfluxDB does have a “continuous query” feature, but forum feedback indicates it may have issues. So we are going the tried and true cron job route, which will run once an hour on the hour indefinitely. Exit out the InfluxDB CLI and run the following shell commands.
mkdir /home/influxdb_scripts
cd /home/influxdb_scripts
nano influx_query.sh
6. Copy and paste the 4 lines below into nano, save, and exit.
#!/bin/sh
influx -execute 'SELECT mean(value) AS value,mean(crit) AS crit,mean(warn) AS warn INTO "home_assistant"."y2_5m".:MEASUREMENT FROM "home_assistant"."autogen"./.*/ WHERE time < now() -26w and time > now() -26w6h GROUP BY time(5m),*' -precision rfc3339 -username 'homeassistant' -password 'yourpassword' -database 'home_assistant'
influx -execute 'SELECT mean(value) AS value,mean(crit) AS crit,mean(warn) AS warn INTO "home_assistant"."inf_15m".:MEASUREMENT FROM "home_assistant"."y2_5m"./.*/ WHERE time < now() -104w and time > now() - 104w6h GROUP BY time(15m),*' -precision rfc3339 -username 'homeassistant' -password 'yourpassword' -database 'home_assistant'
7. Run the following commands to make the script executable and open crontab:
chmod +x influx_query.sh
crontab -e
8. Add the following line to crontab, save, and exit. This will run your shell script once an hour, on the hour, every hour indefinitely. It will also write out a log of the results, so you can always review the last run log output.
0 * * * * /home/influxdb_scripts/influx_query.sh >/backups/log_influx_query.txt 2>&1
9. Run the script manually once, to verify there are no errors. You should see two “written” results. Depending on how old your data is, there may be no data to move so you will see “0“.
./influx_query.sh
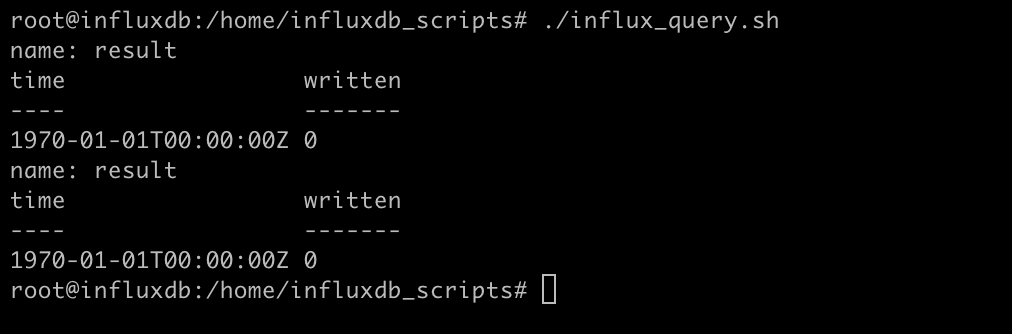
10. Wait for the top of the hour to pass and review the log file to ensure that the file was touched and has results.
Home Assistant Includes/Excludes
Along with InfluxDB downsampling, we can also attack the storage problem from another angle. We can limit the amount of data flowing into the InfluxDB. By default, almost everything gets written to InfluxDB. To limit which what data is being sent to InfluxDB you can use the includes, excludes and ignore_attributes parameters. You can see all the possible parameters and examples in the Home Assistant InfluxDB page.
By using these parameters in your InfluxDB YAML configuration you are basically saying excluded these object types, or only send these objects to InfluxDB. The approach you take all depends on what data you care about for long term storage.
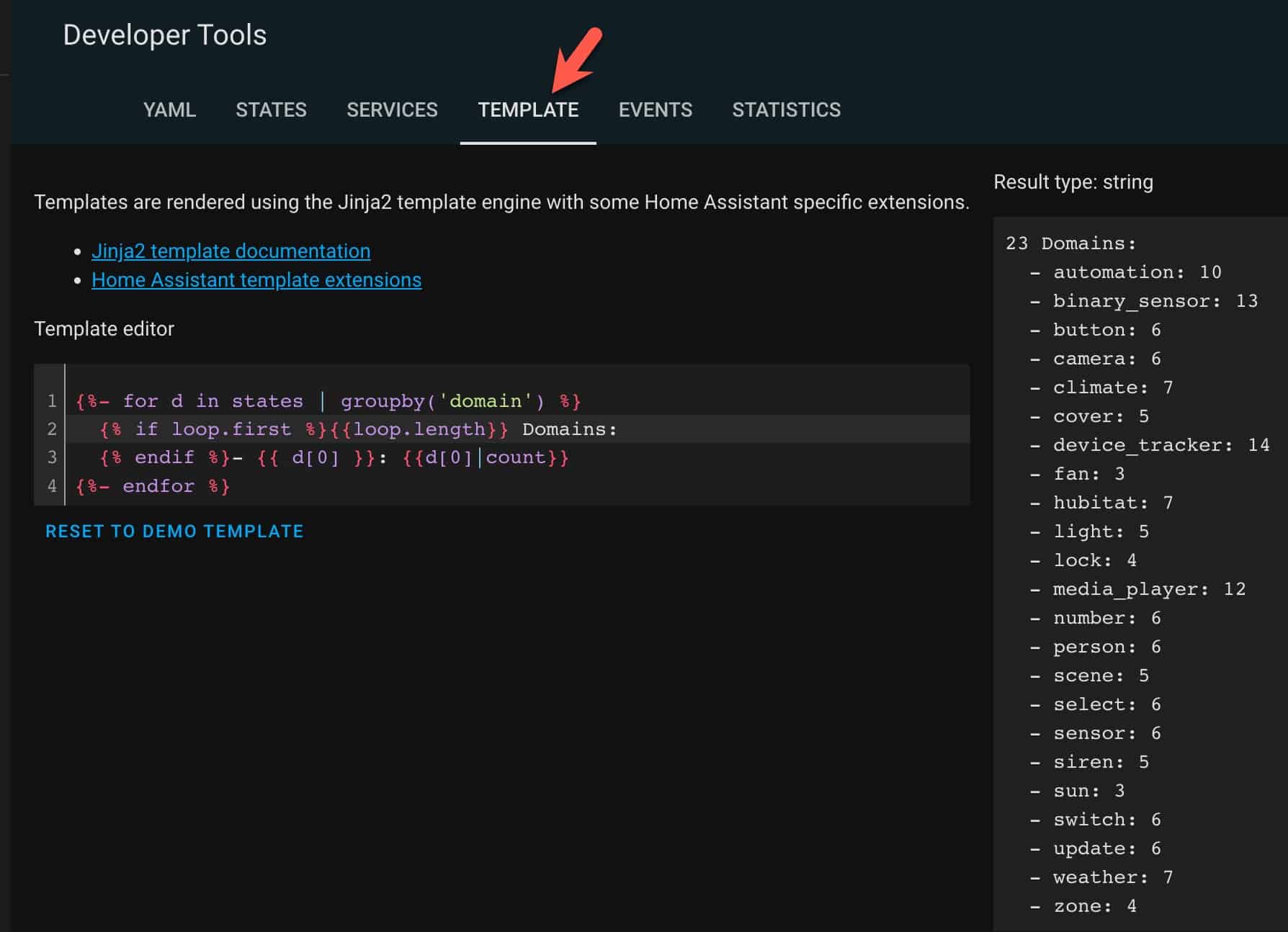
If you want to filter data going into InfluxDB by domain (e.g. camera, person, scene, weather, etc.). you can run the following query in the developer tools section of the HA console to list all of the domains your Home Assistant instance is currently using. In Home Assistant go to the Developer Tools, click on the Template section at the top, then copy/paste the code below. This will list all existing domains in your environment.
Note: Data filtering is totally unrelated to how you’ve installed InfluxDB. So this section works with LXC, Docker, HAOS add-on, bare metal, etc. Data filtering is complimentary with downsampling, so I encourage you to use both options.
{%- for d in states | groupby('domain') %}
{% if loop.first %}{{loop.length}} Domains:
{% endif %}- {{ d[0] }}: {{d[0]|count}}
{%- endfor %}
The YAML below, which you can add to your configuration.yaml file, shows a sample InfluxDB configuration. Your probably already have the first 10 lines, so let’s focus on line 11 and later.
- measurement_attr: Object attribute to use as measurement name.
- default_measurement: Measurement name to use when the measurement_attr state attribute does not exist, e.g. when an entity doesn’t have a unit.
- Source: HA – Adds a “HA” tag in InfluxDB for all data. Can be helpful if you have multiple HA or other data sources flowing in. Easily selectable in Grafana.
- Tags_attributes: These tags and make finding and querying data easier.
- Exclude: Here you can list various types of objects such as domains, entities, to exclude.
- ignore_attributes: You ignore any attributes that you know won’t be useful in the future.
The list of domains and attributes are only examples of what you can filter. Determine what data you want to keep, then build the appropriate include/exclude filters as needed. You can refer to the Home Assistant InfluxDB documentation for more examples.
influxdb:
host: 10.10.10.10
port: 8086
api_version: 1
max_retries: 3
password: !secret influxdb_password
username: homeassistant
database: home_assistant
ssl: false
verify_ssl: false
measurement_attr: unit_of_measurement
default_measurement: units
tags:
source: HA
tags_attributes:
- friendly_name
- unit_of_measurement
exclude:
domains:
- automation
- device_tracker
- scene
- script
- update
- camera
- fan
- lights
- media_player
ignore_attributes:
- icon
- source
- options
- editable
- step
- mode
- marker_type
- preset_modes
- supported_features
- supported_color_modes
- effect_list
- attribution
- assumed_state
- state_open
- state_closed
- writable
- stateExtra
- event
- device_class
- state_class
- ip_address
- device_file
Summary
Using InfluxDB with Home Assistant is a powerful way to store a lot of historical sensor data. However, without some careful thought on what you are storing, how long you are keeping it, and the resolution of the data, you could quickly end up with a huge database. By leveraging downsampling and excluding specific data, you can keep your database manageable. I encourage you to use both approaches: downsampling and includes/excludes. This gives you the most control over what type of data you store in InfluxDB.
By using an InfluxDB LXC container on Proxmox, we keep our Home Assistant backups small which help with the restore process. It also uses less cloud storage, making it a win-win.





Thanks for the step by step guide to setting this up,
Just starting out on my HA + influxDB journey. and the one thing I did not find is what retention policy you used for the raw (first 6 month), or am I missing something obvious.
All data is kept for the first six months.
Derek, Thanks for your awesome guides! It really helped me to do my proxmox setup on a HP Elitedesk mini PC.
I did a complete new setup using proxmox for HAOS and InfluxDB and also planning to make a Grafana VM.
In Influxdb I created the 3 databases as you mentioned, but I don’t see any data coming yet into the “inf_15m”
Most probably because the query only selects data from the “autogen” database which is at least 26 weeks old?
My recent HA data in “autogen” is visible in the Chronograf Explore window.
Can I change the query to 4weeks (temporarely) to see if the inf_15m database receives data via the hourly cronjob ? Why wait for half a year?
THe inf_15m will only get data after 26 weeks. This leaves week 1-26 as high resolution data. I figured most people wouldn’t need ‘high res’ data for more than 6 months in the past.
Hi Derek,
thank you for the tutorial. Really helpful.
Can you please advise what the crit and warn data is used for?
Would it be possible to not only store the mean but also the min and max values? How?
And most important question for me: I have influxdb as an integration within HomeAssistant which is running within a Proxmox VM and I want to migrate the existing sensor data in the LXC influxdb? How can I do this?
For me it would be sufficient to keep the raw data for just 5 weeks until they can be downsampled into 5min data (mean, max, min) and after 3 months hourly data, and after a year daily data
Hey Derek,
I was following your guide on a test system to see how it goes and it did the trick to reduce the DB footprint significantly.
What I didn’t notice however is that the backup did not shrink: somewhat counterintuitively I now have a 13 GB database producing 21 GB backups.
My first Guess was that The shards were not deleted as they still contain (less) data for their respective period of time – but that wouldn’t explain why the actual footprint on disk is now significantly smaller.
I use the recommended portable backup capability of InfluxDB.
What are you experiences?