A great new feature in Windows Server 2012 is data deduplication. Data deduplication uses sub-file variable-size chunking and compression, which together deliver optimization ratios of 2:1 for general file servers and up to 20:1 for Hyper-V virtualization data. Microsoft has some great articles on dedupe, such as this one and a list of Powershell cmdlets here.
Major features include:
- Scale and performance. Windows Server 2012 data deduplication is highly scalable, resource efficient, and nonintrusive. It can run on dozens of large volumes of primary data simultaneously without affecting other workloads on the server. Low impact on the server workloads is maintained by throttling of CPU and memory resources consumed.
- Reliability and data integrity. Windows Server 2012 leverages checksum, consistency, and identity validation to ensure data integrity. And, for all metadata and the most frequently referenced data, Windows Server 2012 data deduplication maintains redundancy to ensure that the data is recoverable in the event of data corruption.
- Bandwidth efficiency in conjunction with BranchCache. Through integration with BranchCache, the same optimization techniques are applied to data transferred over the WAN to a branch office. The result is faster file download times and reduced bandwidth consumption.
- Optimization management with familiar tools. Windows Server 2012 has optimization functionality built into Server Manager and PowerShell. Default settings can provide savings immediately or fine-tune the settings to see more gains. Easily use PowerShell cmdlets to kick off an optimization job or schedule one to run in the future. Turning on the Data Deduplication feature and enabling deduplication on selected volumes can also be accomplished using an unattended .xml file that calls a PowerShell script and can be used with Sysprep to deploy deduplication when a system first boots.
Data deduplication involves finding and removing duplication within data without compromising its fidelity or integrity. The goal is to store more data in less space by segmenting files into small (32KB to 128 KB) variable-sized chunks, identifying duplicate chunks, and maintaining a single copy of each chunk. Redundant copies of the chunk are replaced by a reference to the single copy, the chunks are organized into container files, and the containers are compressed for further space optimization.
According to Microsoft’s blog article here, real-world performance impact is very minimal. Optimization rate for a single job runs about 100GB/Hr. Multiple volumes can be processed in parallel.
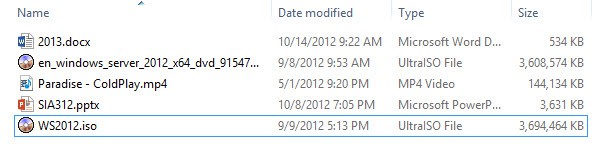
Let’s see how easy it is to configure data deduplication, and what kind of space savings we see. As a test I have the original 3.6GB ISO image of Windows Server 2012, and I have a modified version of the ISO that has additional files and software shoved inside. So 99% of the content is the same, but as you can see from the file sizes they are different. This file share is being shared from my file share cluster, created via my blog article here.
Now let’s configure data deduplication and see what kind of savings we see.
1. First we need to locate the volume on the file share cluster that is hosting my data. After locating the volume, just right click on it and select Configure Data Deduplication.

2. A wizard opens up where you can configure various parameters, such as minimum file age (which can be set to 0 to ignore age limits), configure file type exclusions, and setup the all important dedupe schedule.

3. The scheduler has several options, and lets you configure dual schedules. Perhaps one schedule for week days, and another schedule for the weekend.

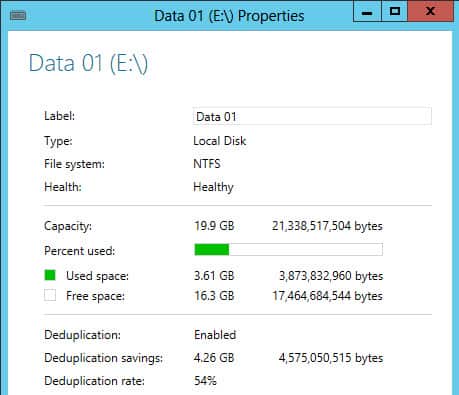
4. After configuring the dedupe schedule, I came back to the system a day later (to let the scheduler kick in and my minimum file age of 1), and viola! 54% dedupe rate and saved 4.26GB.





Good article. I use Veeam Backup & Replication to backup my VMs to a standard vDisk from my HP EVA 8100, and the lack of dedupe across backup jobs has always annoyed me, though I do understand the benefits of portal backups.
I tested Server 2012’s dedupe with some Veeam Backups and the results were amazing. I was saving up to 80% or more depending on the data. Fantastic!
Microsoft claim their dedupe can save over 90% of space used by Virtual Machines. I have to question this, however. Is it really wise to try and deduplicate your running VMs? I wouldn’t have thought so. If someone can show me there is zero performance impact I’d be impressed, but there is an overhead, however small.
I am really looking forward to upgrading my two primary file servers (about 4-5TB of data each) to Server 2012 and enabling deduplication. Data sprawl and sizes are just getting out of control.
Hopefully HP, Symantec, Commvault, etc can all implement ways to intelligently backup this data without have to rehydrate before writing to tape, although I don’t know if this will be possible.