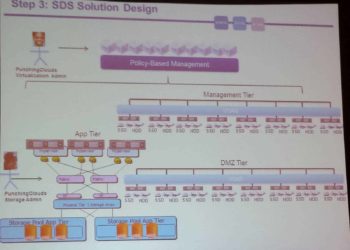
VMworld 2014: SDDC VCDX Panel
Session: INF1736 Jon Kohler (Nutanix), Josh Odgers (Nutanix), Matt Cowger (EMC), Scott Lowe (VMware), Jason Nash (Varrow) This was a very lively session with a panel of five VCDXs from a variety of companies. I was taking real time notes, so I didn't capture all of comments and some of...